-
Docker로 쉽게 올리는 나만의 Apt 미러 서버
안녕 독자들. 문득 그런 생각이 들었다. 흔히
apt-get명령어를 통해 필요한 패키지를 쉽게 다운로드 받고, 그게 익숙한 것이 되다 보니 마치 수도꼭지에서 물 틀어 마시듯 당연하게 사용하고 있는데, 만약 무슨 일이 생겨 APT 패키지를 제공하는 서버가 내려간다면?사실 그래서 존재하는 것이 미러 (Mirror) 서버다. 원본 서버가 제공하는 정보들을 복제해 다른 경로를 통해 다시 제공하는 것. 꼭 APT가 아니더라도 음악 미러, 동영상 미러 사이트 등의 이름으로 일반인에게도 나름 친숙한 개념이 되었다.
이미 국내외 다양한 개인, 단체가 제공하는 APT 미러 서버가 있어 한두곳이 내려간다고 해도 사실 행복한 리눅스 라이프에는 큰 지장이 없지만, 그 미러 서버, 우리도 돌려볼 수 있지 않을까?
직접 미러를 운영한다면 나에게는 언제나 믿고 접근할 수 있는 든든한 APT 백업이 생기는 것이고, 다른 유저들에게는 APT를 사용할 때 선택 폭이 넓어지는 선순환이 될 수 있다. 꼭 퍼블릭하게 공유하지 않더라도, 예를 들어 사내 폐쇄 망에 붙어 돌아가는 서버가 APT를 통한 패키지 설치, 업데이트가 필요할 경우 자체 미러 서버를 운영해 폐쇄 망과 연동시키는 등 활용도는 무궁무진하다. 극단적으로 생각하면 재난 상황 등 인터넷 망이 날아간 상황에서도 리눅스 서버를 세팅하겠다는 뼈브옵스, 뼈발자 분들에게도 도움이 될 수 있겠고.
깊게 생각하지 않아도, 커뮤니티의 일원이 된다는 것은 언제나 매력적인 일이다. 그 커뮤니티의 일부로서 스스로가 기여한 무언가가 훗날 많은 사람들에게 도움이 된다면 더할 나위 없지 않을까.
내 컴퓨터에서 APT는 어떻게 동작할까?
백문이 불여일견이라고, 아리송한 것도 일단 해보면 감이 잡히겠지만, 그 ‘아리송’ 한 상태부터 되기 위해서는 약간의 이론 지식이 필요하다.
지금 데비안 계열 OS를 사용하고 있다면,
/etc/apt/sources.list파일을 열어 보자. 아래와 같은 내용이 담겨 있을 것이다.# See http://help.ubuntu.com/community/UpgradeNotes for how to upgrade to # newer versions of the distribution. deb http://archive.ubuntu.com/ubuntu/ bionic main restricted # deb-src http://archive.ubuntu.com/ubuntu/ bionic main restricted ## Major bug fix updates produced after the final release of the ## distribution. deb http://archive.ubuntu.com/ubuntu/ bionic-updates main restricted # deb-src http://archive.ubuntu.com/ubuntu/ bionic-updates main restricted (...)빼곡하게 적혀있는 URL의 앞에 적혀있는
deb는,.deb확장자로 만들어진 데비안 애플리케이션 패키지를 뜻한다.deb-src는 패키징이 이루어지지 않은 애플리케이션 소스, 그리고 추후의 패키징을 위해 패키지명 정보 등을 담은dsc(데비안 컨트롤 파일) 이 되시겠다. 즉, 위 예시 파일은 저장소에서 이미 패키징이 된deb파일만 다운로드 받겠다라는 뜻이 된다.저장소 URL - http://archive.ubuntu.com/ubuntu/ 은 우분투에서 자체적으로 제공하는 1차 아카이브 (우분투 직속) 저장소에 연결하는 링크다. 일반적으로 사용되는 것은
http지만, APT는ftp등 파일 전송이 가능한 다양한 프로토콜을 함께 지원한다.그 뒤에 따라오는
bionic은 우분투의 버전 코드네임 (18.04 LTS),main,restricted,universe,multiverse는 저장소에 올라와 있는 애플리케이션이 무료인지, 코드가 완전히 공개되어 있는지, 유료 라이센스가 필요한지 등에 따라 정리해둔 일종의 카테고리라 생각할 수 있겠다. 관련하여 자세히 알고 싶다면 이 링크를 참조하자.우리가 APT를 사용하기 위해
apt-get update명령어를 사용하게 되면, APT는 방금 위에서 살펴본/etc/apt/sources.list파일을 기반으로 저장소를 읽어 다운로드 받을 수 있는 프로그램들의 리스트를 만들게 된다. 해당 리스트는/var/lib/apt/lists에서 확인할 수 있다.리스트를 갱신한 후
apt-get install명령어를 사용하면 해당 리스트에서 내가 원하는 애플리케이션이 존재하는지 확인한 후,sources.list에 명시된 원격 저장소에서 패키지를 다운로드해 와 로컬 머신에 설치하게 된다.그리고 예상했겠지만, 우리의 APT 미러 서버가 완성될 경우 이
sources.list에 적혀있는 원격 저장소 URL을 우리 것으로 바꿔줄 것이다.대충 내 컴퓨터에 설치된 APT가 무엇을 담고 있는지 살펴봤으니, 본격적으로 미러를 구성해보자.
미러 서버 올리기
구조부터 살펴볼까?
APT 미러는 기본적으로
deb와deb-src가 잔뜩 담겨있는 보따리에 불과하기에, 이론적으로는 온라인에서 파일을 끌어올 수 있는 어떤 도구를 사용하더라도 구축할 수 있지만, 최근에는[apt-mirror](https://apt-mirror.github.io/)라는 도구가 마치 표준처럼 널리 사용되고 있다. 언제나 미리갈려나간고생해준 개발자에게 묵념.널리 사용되는 도구인 만큼 APT 리스트에도 올라가 있어 당장 우분투 등의 OS에서
apt-get install apt-mirror명령어를 통해 설치할 수도 있지만, 조금 더 편리하고 깔끔한 구성을 위해 필자가 도커화시켜 명령어 한 줄이면 모든 것을 실행할 수 있게 이미 다 준비해 두었다. kycfeel/dockerized-apt-mirror 에서 전체 구조를 살펴볼 수 있다.Git 저장소를 다운로드 받은 후,
mirror.list파일을 먼저 살펴보자. 마치 조금 전 확인했던/etc/apt/sources.list파일처럼, 원격 APT 저장소에 대한 링크와 카테고리 등이 명시되어 있다.APT 서버를 직접 구동한다고 해도, 결국 그 안에 들어갈 패키지들은 이미 구비되어 있는 어딘가에서 끌어와야 한다.
apt-mirror는 바로 이 파일에 명시된 원격 저장소에서 각 OS 혹은 버전별 패키지들을 다운로드 (미러링) 한다. 글 작성 시점 (2019년 7월 16일) 기준으로, Git에 올려둔mirror.list에는 우분투 공식 저장소 에서 16.04 LTS, 18.04 LTS, 19.04 LTS, 그리고 19.10의 패키지들을 미러링 하도록 명시해 두었다. 물론 필요에 따라 얼마든지 다른 저장소나 버전을 추가할 수 있겠다.파일에 문제가 없다면, 이제
crontab/apt-mirror을 열어보자. 이곳에는 어느 주기로 원격 저장소에서 파일을 다시 받아올 지 명시하는 crontab 규칙이 담겨 있다. 중요한 부분은 파일 맨 앞에 있는 cron 주기 표시다. 기본은0 4 * * *, 매일 오전 4시에 (UTC)apt-mirror명령어를 다시 실행하도록 설정해 두었다. 본인의 필요에 따라 수정을 권장하고, cron 규칙이 영 무섭게 생겼다면 crontab.guru 사이트가 도움의 손길을 내밀어줄 것이다.마지막으로 postmirror.sh 다.
apt-mirror는 매번 원격 저장소에서 파일을 다운로드 한 후 이 스크립트를 실행해 마무리 작업을 한다. 의무적으로 무언가 요구되는 작업은 없어 이 파일을 공백으로 내비 둬도 상관 없지만, Git 저장소에 올린 파일에는 이 곳에apt-mirror의 내부/var/spool/apt-mirror/var/clean.sh스크립트를 명시해 둬 다운로드 후 더 이상 필요 없는 찌꺼기를 알아서 지울 수 있게 해뒀다.docker-compose.yaml을 열어보면 방금 확인했던 파일들을 볼륨의 형태로 마운트해apt-mirror컨테이너 사용한다는 것을 알 수 있다.volumes: - ./apt-mirror-volume:/var/spool/apt-mirror - ./postmirror.sh:/var/spool/apt-mirror/var/postmirror.sh - ./mirror.list:/etc/apt/mirror.list - ./crontab:/etc/cron.d추가적으로,
volumes단락의 맨 위,apt-mirror-volume은apt-mirror도커 컨테이너가 다운로드 받은 APT 미러 데이터를 저장하는 경로다. Git 폴더에 있는 그apt-mirror-volume맞다. 만약 Git 문제 (변경사항을 초기화 한다던지)로 다운로드 받은 APT 데이터의 손상이 걱정된다면 Git 폴더 외부에 따로 저장용 경로를 만든 후apt-mirror-volume으로 심볼릭 링크를 걸어주는 것을 추천한다. 아니면docker-compose파일 자체를 편집해도 되고. Up to you.진짜로 실행하기
구조를 하나하나 찬찬히 모두 살펴봤으니, 이제 정말 서버를 실행할 때가 왔다. 아래 명령어 한 줄 이면 충분하다. 괜히 도커가 있는게 아니다.
docker-compose up -d기본 옵션으로는, 첫 실행 시 로컬 머신에서 직접 도커 이미지를 빌드한다. 만약 이 과정을 생략하고 싶다면, Docker Hub의
kycfeel/dockerized-apt-mirror저장소에서 언제나 최신 이미지를 다운로드 받을 수 있다. 원하는 버전 태그를 잘 확인하고 사용할 것.컨테이너가 올라갔다면,
docker logs <apt-mirror-컨테이너-이름>으로 정상적으로apt-mirror가 실행되고 있는지 확인하자. 처음 실행이라면, 약 500GB ~ 600GB 정도의 파일이 다운로드 될 것이다. 다운로드에는 수 시간이 소요될 수 있다. 만약 용량이 너무 부담스럽다면, 상단의mirror.list를 수정해 필요없는 저장소를 제외하도록 하자.(...) Running the Post Mirror script ... stdout 03:27:49 (/var/spool/apt-mirror/var/postmirror.sh) stdout 03:27:49 stdout 03:27:53 Removing 309 unnecessary files [239.2 MiB]... stdout 03:27:56 [0%]...............................done. stdout 03:27:56 stdout 03:27:56 Removing 0 unnecessary directories... stdout 03:27:56 done. stdout 03:27:56 stdout 03:27:56 stdout 03:27:56 Post Mirror script has completed. See above output for any possible errors. (...)위와 같은 로그와 함께 모든 다운로드가 완료되었다면,
http://<나의_도메인>/ubuntu주소를 통해 미러에 접근할 수 있다. 아래와 같은 파일 구조가 보인다면 정상적으로 설치된 것이다.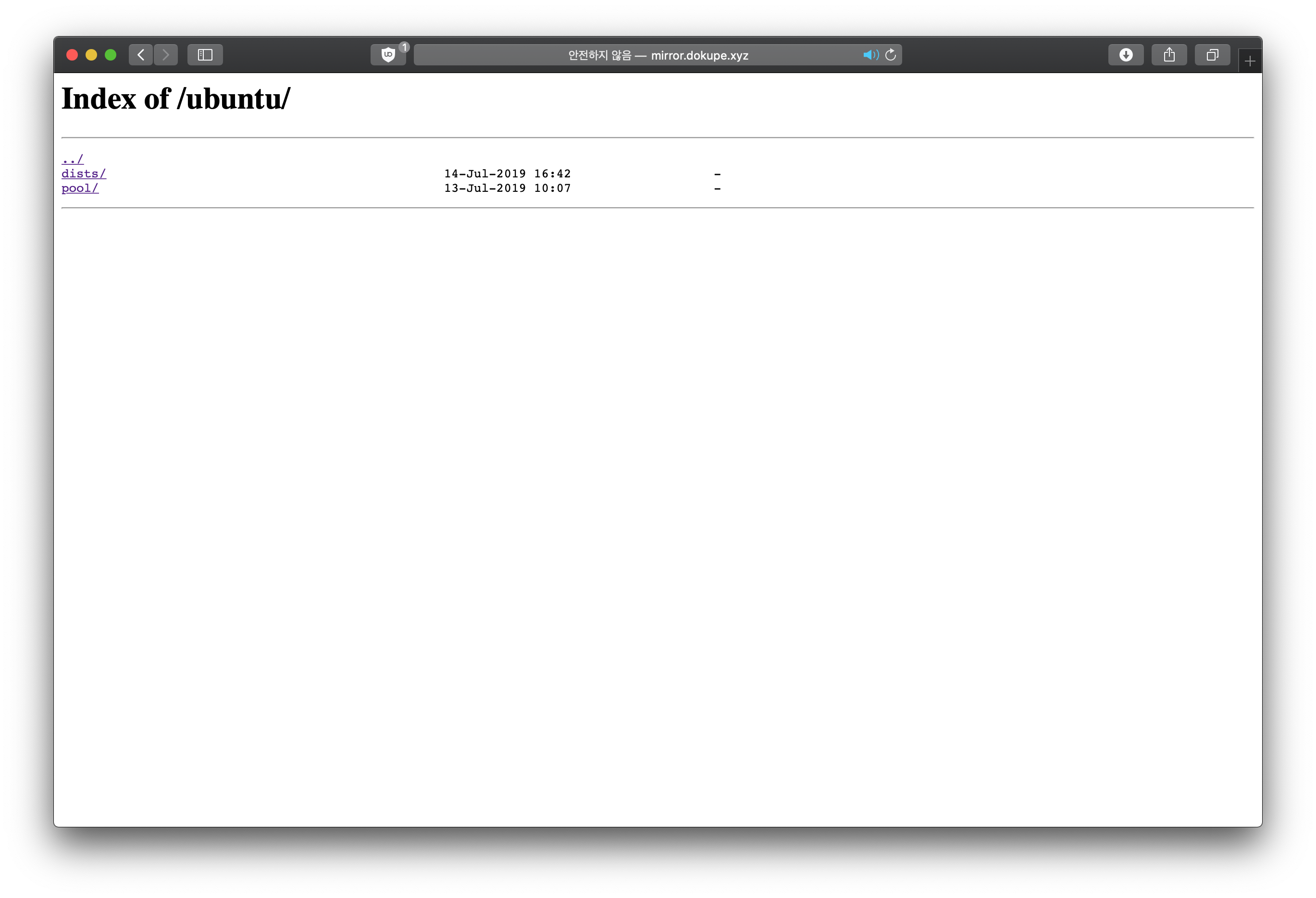
이제, 미러가 정말 제대로 동작하는지 확인할 차례다. 우분투 OS의
/etc/apt/sources.list에 들어가 이미 적혀있는 저장소의 주소 (http://archive.ubuntu.com,http://security.ubuntu.com) 를http://<나의_도메인>/ubuntu로 변경한 후,apt-get update명령어를 실행해 정상적으로 데이터를 받아오는지 확인하자.어떠한 오류도 없었다면, 축하한다. 내 미러가 정상적으로 동작한다는 소리다. 이제부터
apt-get명령어를 통해 설치하는 모든 패키지는 내 미러에서 직접 날아올 것이다.apt-get install -y curl명령어를 통해 시범으로curl을 설치해보자. 로그에 내 미러 도메인이 보이는가? 무언가 뿌듯한 느낌이 든다.정리하며
“인프라”를 구축한다는 것은 다른 것에서는 느끼지 못할 짜릿함이 있다. 평소에는 받아만 쓰던 무언가를 직접 손대고 일으킨다는 것이 종종 짜증으로 느껴질 때는 있지만, 완성된 뒤 많은 사람들이 내가 세운 이것을 발판삼아 상상치도 못했던 멋진 일들을 펼칠 수 있다는 건 무엇도 대체하지 못하는 뿌듯함을 나에게 돌려준다.
방금 우리가 만든 APT 미러도 “인프라” 의 정의에 명확하게 부합한다. 이 미러가 존재하기에, 사람들은 필요한 패키지를 설치할 때 더 많은 선택권을 가질 수 있고, 이를 적절하게 사용함으로써 빠르게 설치된 패키지를 가지고 멋진 무언가를 조금이나마 수월하게 만들어나갈 수 있다. 여러분은 방금 전 지구적 IT 커뮤니티에 지대한 기여를 하셨습니다. 짝짝. 정말이예요.
필자가 구축한 APT 미러 서버는 아래의 정보를 참고해 접근할 수 있다. 별다른 일이 없다면 24시간 365일 구동되며, 매일매일 새로운 패키지를 받아온다. 많은 혹사를 기대하겠습니다. 꾸벅.
(http | https)://mirror.dokupe.xyz/ubuntu
- Ubuntu 16.04 LTS
- Ubuntu 18.04 LTS
- Ubuntu 19.04
- Ubuntu 19.10 (Latest!)
-
Helm으로 손쉽게 Kubernetes에 애플리케이션 배포하기

쿠버네티스에 배포하는 모든 종류의 리소스 (디플로이먼트, 서비스, 인그레스 등)은 모두
yaml파일에 작성된 폼을 기반으로 구성된다. 사용자가 할 일은 열심히yaml파일을 작성한 후,kubectl apply명령어로 파일을 적용시키기만 하면 끝.그런데, 본격적으로 쿠버네티스에 이것저것 올리다 보면 뭔가 아쉬울 때가 있다. 한 애플리케이션을 위해 여러
yaml파일을 적용해야 하는 경우, 비슷한 뼈대를 바탕으로 해 다른 일을 처리하는 애플리케이션을 만드는 경우 등 생각보다 기본yaml파일을 단순히 적용하는 것 이상의 “무언가”에 갈증을 느끼게 된다.오늘 들고 온
Helm이 바로 여러분이 찾던 그 “무언가” 다. 너무나도 매끄럽게 잘 작동하는 패키지 매니저로서,Helm을 위해 미리 준비한Helm Chart만 있으면 마치.exe프로그램을 설치하듯, 쿠버네티스라는 내 컴퓨터에 내 애플리케이션을 뚝딱 설치할 수 있다.깨끗한 쿠버네티스 클러스터를 준비한 후, 아래 글을 쭉 따라와보자. 곧
Helm의 매력에 푹 빠질 것이다.Helm 설치하기
마치 쿠버네티스 클러스터에 접근하기 위해서는
kubectl이 필요하듯,Helm을 쿠버네티스 클러스터에 설치하고 애플리케이션을 배포하기 위해서는Helm클라이언트가 필요하다.macOS에서는
brew를 통해 아래 명령어로 간단히 설치할 수 있다. 다른 OS에서는 이 가이드 를 참고하자.만약 로컬에
kubectl이 설치되어 있지 않을 경우, 아래 명령어가kubectl까지 같이 설치합니다. 설치되어 있을 경우라도 최신 버전으로 자동으로 업데이트 하니 만약 구버전kubectl또는helm이 필요할 경우 특정 버전을 지정하여 설치하시기 바랍니다.brew install kubernetes-helm설치가 완료된 후
helm version명령어를 통해 정상적으로 설치가 진행되었는지 꼭 확인하자. 지금은 서버 측에helm이 준비되지 않아Client:로 시작하는 로컬Helm정보만 출력될 것인데, 정상이다.클라이언트가 제대로 준비되었다면, 이제 쿠버네티스에
Helm을 설치할 차례다.Helm은Tiller라는 특수한 Pod를 통해 쿠버네티스 위에서 리소스를 생성하고 지우는데, 자유롭게 쿠버네티스를 쥐락펴락 할 수 있어야 하기 때문에 그에 맞는 권한을 할당해줄 필요가 있다.아래 코드를
yaml파일에 저장해kubectl apply하자. 아래yaml은Tiller라는cluster-admin에 연결된 새로운 권한을 생성한다.apiVersion: v1 kind: ServiceAccount metadata: name: tiller namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: tiller roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: tiller namespace: kube-system이제
Tiller를 쿠버네티스 위에 올리면서, 방금 생성한 권한을 부여해 보자.helm init --service-account tiller완전히
TillerPod가 준비될 때까지 잠깐 기다린 후,helm version명령어를 다시 실행해 서버 측에도 완전히Helm이 준비되었는지 확인하자. 준비가 되었다면 아래와 같은 값이 출력될 것이다.필자는 구버전
helm이 설치되어 있는 테스트 환경에서 명령어를 실행해 버전이v2.9.1로 표시되었다. 글을 작성하는 현재 최신helm은v2.13.0이다.$ helm version Client: &version.Version{SemVer:"v2.9.1", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"} Server: &version.Version{SemVer:"v2.9.1", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"}Helm Chart로 애플리케이션 실행하기
Helm이 준비되었다면, 이제Helm Chart가 필요하다. 마치 윈도우 컴퓨터에 설치하는.exe패키지처럼, 쿠버네티스라는 컴퓨터를 위한 애플리케이션 패키지를 구해오는 것이다.만약 실행하려고 하는 것이
ElasticSearch나Jenkins같은 잘 알려진 오픈소스 애플리케이션일 경우, 대부분 해당 제작사에서Helm Chart를 같이 제작해 배포한다. 이런Chart들은Helm Stable Repo에서 확인할 수 있다.Helm패키지 설치는helm install명령어를 통해 이루어진다, 적당한 패키지를 고르지 못했다면, 필자가 만든 데모용 애플리케이션을 설치해보며 어떻게Helm을 사용할지 감을 잡을 수 있다.먼저 이 링크에서 데모
Helm Chart를 다운로드 받은 후, 압축을 풀고, 적당한 텍스트 에디터로 열어보도록 하자. 구조는 아래와 같을 것이다.Helm Chart설치는tgz로 압축된 상태에서도 가능하지만, 이번에는 실습을 위해 압축을 해제했습니다. 물론 압축 해제된 폴더 그 자체로도 설치가 가능합니다.├── Chart.yaml ├── charts ├── templates │ ├── NOTES.txt │ ├── _helpers.tpl │ └── deployment.yaml └── values.yaml아래 명령어를 통해 쿠버네티스에 올려보도록 하자.
쿠버네티스의 모든 동작이
yaml파일을 기반으로 이루어지는 것처럼,Helm Chart도 결국에는yaml파일들의 집합체이다.Helm Chart설치를 진행하면templates폴더 안에 있는 모든yaml을 실행한다. 예시를 확인하기 위해deployment.yaml파일을 열어보자. 내용은 아래와 같을 것이다.apiVersion: apps/v1beta2 kind: Deployment metadata: name: helm-helloworld labels: app: helm-helloworld chart: helm-helloworld spec: replicas: 1 selector: matchLabels: app: helm-helloworld template: metadata: labels: app: helm-helloworld spec: containers: - name: helm-helloworld-container image: "alpine:3.6" env: - name: PRINT_VALUES value: command: ["/bin/sh","-c"] args: - while true; do echo $PRINT_VALUES; sleep 5; done;일반적으로 보던 디플로이먼트를 생성하는
yaml같아 보이지만, 못 보던 무언가가env칸에 있다. 여기서Helm의 진가 중 하나가 들어난다. 바로 파라미터화다. 같은yaml파일이여도 동적으로 어떤 값을 넘겨주냐에 따라 다른 결과물을 만들 수 있다. 그리고 그 값들은Helm Chart최상위 경로에 있는values.yaml에 정의된다.values.yaml파일을 열어보면 아래와 같은 값이 먼저 정의되어 있을 것이다.printValues: "hello world!"printValues값이hello world!로 정의되어 있다. 대충 감을 잡으셨겠지만, 이대로Helm Chart를 쿠버네티스에 설치하면hello world!를 5초에 한번씩 출력하게 될 것이다. 출력 문구를 바꾸고 싶다면, 이걸 수정하면 된다.일단 대충 구조를 파악했으니, 쿠버네티스에 설치부터 해보자. 아래 명령어를 참고하자.
helm install --name helm-demo --namespace default <압축해제한_HELM_경로>우리는 방금 필자가 만든 데모용
Helm Chart를helm-demo라는 설치 이름으로default네임스페이스에 설치하였다.이제
kubectl get pods명령어로 방금 실행한 애플리케이션의 Pod 이름을 확인한 후,kubectl logs pod/<확인한_POD_이름>명령어를 통해 로그를 긁어와보자.$ kubectl logs helm-helloworld-8d6f9c5db-84pjv hello world! hello world! hello world! hello world! hello world!정상적으로 Pod가 실행되어 로그를 출력하고 있는 것을 확인할 수 있다.
kubectl get deployments명령어로 디플로이먼트도 제대로 생성되었는지 체크하자.Helm으로 새로운 애플리케이션을 생성해 봤으니, 이제 업그레이드도 해보자. 하는 김에 출력될 문구를 바꿔봐도 좋겠다.helm upgrade helm-helloworld --set printValues="hello helm!" <압축해제한_HELM_경로>잠시 기다린다면 새로운 Pod가 새로운 값을 읽고 시작되어, 아래와 같이
hello world!대신hello helm!이라는 문구를 출력할 것이다.$ kubectl logs helm-helloworld-8d6f9c5db-5p1bj hello helm! hello helm! hello helm! hello helm! hello helm!이처럼
Helm은 애플리케이션 설치와 업그레이드 시 동적으로 값을 바꿀 수 있게 해준다. 이를 잘 응용해 업그레이드 시 도커 이미지의 버전을 바꾸는 등의 사용도 얼마든지 가능하다. 만약 업그레이드를 하는데 이전에 넘긴 값을 그대로 쓰고싶다면--reuse-values파라미터를 같이 넘기면 된다.자. 작동 되는것도 잘 봤고 적당히 가지고 놀았으니 이제 깔끔하게 정리할 차례다. 현재 설치되어 있는
Helm Chart들은helm ls명령어로 확인할 수 있다. 우리가 설치한Helm Chart의 이름은helm-helloworld이니 아래 명령어를 통해 완전히 삭제할 수 있다.helm del --purge helm-helloworld완전히 삭제된 후, 다시
helm ls명령어를 실행해 다시한번 확인해보는 것도 좋다.더 알고싶어요!
방금까지 첫
Helm사용에 필요한 건 대충 다 해봤다. 이제 본격적으로 배포에Helm을 사용하고 싶으신 분들은 아래 글들을 참고하면 도움이 될 것이다.-
MS 공식
Helm사용 가이드. 위에서 다룬 것처럼 깡통 상태에서부터Helm을 셋업하고 쓸 수 있도록 도와준다. - https://docs.microsoft.com/ko-kr/azure/aks/kubernetes-helm -
Helm 공식 사용 안내 페이지. - https://helm.sh/docs/using_helm/
-
-
eksctl로 구축하는 AWS EKS Kubernetes 클러스터

이전 글 에서 kubeadm을 사용해 베어메탈 쿠버네티스 클러스터를 구축하는 법을 다루었는데, 아무래도 실 서비스 환경에서는 조금 더 관리할 것이 덜하고 안정적인 무언가가 필요하다.
그런 생각을 하는 사람은 필자와 우리 독자 뿐만 아니라, 쿠버네티스를 프로덕션에 사용하고 싶어하는 모든 개발자들이 하고 있다. 개발자가 상상한다면 반드시 결과물이 나오는 법. 이미 세상에는 구글, 아마존, MS 등이 제공하는 다양한 관리형 쿠버네티스 서비스들이 나와있다.
그 중 오늘 우리는 아마존에서 제공하는 AWS EKS를 사용해 클러스터를 구축해볼 것인데, 이게 좀 불편하다. 좀 많이 불편하다. 분명 불굴의 아마존이 제공하는 안정적인 서비스이고, 기존에 익숙하게 사용하던 여러 AWS 서비스들과 연동된다는 점은 참 좋은데, 초기 구축이 타 관리형 쿠버네티스와 비교해 많이 불편하다.
그래서 등장한 도구가 바로
eksctl이다. 이미 쿠버네티스 네트워크 플러그인인Weave Net을 선보여 익숙한 분들도 있을 Weaveworks가 제작한 CLI 도구다. EKS 클러스터의 생성과 업그레이드, 삭제까지 모두 간단한 명령어 몇 줄로 해결할 수 있게 해주는 사랑스러운 놈이다.아래로 진행하기 전, 사용할 수 있는 AWS 계정과 EC2 / EKS 접근이 가능한 IAM 엑세스 키, 그리고
aws-cli를 설치해두길 바란다.eksctl은 설치되어 있는aws-cli에 의존해 계정 인증을 하고 작업을 진행한다.그래서 언제 써보나요?

지금부터 쓸꺼다. 바로 지금.
macOS 기준으로 Homebrew를 사용한다면, 아래 명령어로 쉽게 설치할 수 있다.
brew tap weaveworks/tap brew install weaveworks/tap/eksctl타 Unix-like 운영체제에서는 아래 명령어로 설치할 수 있다.
curl --silent --location "https://github.com/weaveworks/eksctl/releases/download/latest_release/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp sudo mv /tmp/eksctl /usr/local/bin모든 설치가 완료되었다면, 이제 바로 클러스터 하나 뚝딱 만들 수 있다. 아래는 기본적인 파라미터가 포함된 예제 명령어다.
더 많은 옵션은 eksctl 공식 문서에서 찾아볼 수 있다.
eksctl create cluster --name=<클러스터_이름> --nodes=<worker_node_갯수> --node-type=<EC2_인스턴스_종류> --region=<AWS_REGION> --kubeconfig=<KUBECONFIG_저장_경로>꽤나 직관적이다. 이제 한 10여분 기다리면 별다른 함정(?) 없이, 내가 지정한 AWS 리전에 지정한 이름, Worker 갯수, KUBECONFIG까지 깔끔하게 생성해 저장해준다.
생성이 완료된 클러스터의 KUBECONFIG 파일을 열어보면 아래와 같은 값들이 있을 것이다.
(...) current-context: (...) kind: Config preferences: {} users: - name: (...) user: exec: apiVersion: client.authentication.k8s.io/v1alpha1 args: - token - -i - (...) command: aws-iam-authenticator env: null아래에
aws-iam-authenticator가 보이는가? AWS EKS 클러스터가 계정 인증 처리를 위해 사용하는 소프트웨어다.우리가 쿠버네티스 명령어를 실행하면 바로 저
aws-iam-authenticator가 계정 인증을 마친 후 실제 쿠버네티스 API에 전달될 것이다.eksctl과 마찬가지로,aws-cli에 로그인된 엑세스 키 정보를 사용한다.macOS 기준으로 아래처럼 설치하면 된다. 아래 링크가 너무 오래되었거나 타 운영체제를 사용할 경우 이 링크를 참조하면 좋다.
curl -o aws-iam-authenticator https://amazon-eks.s3-us-west-2.amazonaws.com/1.10.3/2018-07-26/bin/darwin/amd64/aws-iam-authenticator chmod +x ./aws-iam-authenticator cp ./aws-iam-authenticator $HOME/bin/aws-iam-authenticator && export PATH=$HOME/bin:$PATH echo 'export PATH=$HOME/bin:$PATH' >> ~/.bash_profile이제
aws-iam-authenticator help를 테스트로 실행해봐 제대로 작동하는지 확인하자. 정상적으로 도움말이 뜬다면 성공.aws-cli까지 제대로 로그인 된 것을 확인했다면, 아래 명령어로 KUBECONFIG를 지정한 후, 간단히 클러스터 정보를 받아와보자.export KUBECONFIG=<내_KUBECONFIG_파일_경로> kubectl get node별다른 계정 오류 등이 발생하지 않고 아래와 같이 내 클러스터의 Worker 노드 정보가 뜬다면 정상적으로 연결된 것이다.
NAME STATUS ROLES AGE VERSION (...).compute.internal Ready <none> 1d v1.11.5 (...).compute.internal Ready <none> 1d v1.11.5 (...).compute.internal Ready <none> 1d v1.11.5AWS EKS는 생성 과정만 조금 다를 뿐, 한번 생성되면 일반적인 Kubernetes와 아주 똑같다. 이제 아래 문서들을 참고해 웹 대시보드나 Helm 등을 설치하고 본격적으로 내 워크로드들을 올릴 수 있다.
클러스터 정보 업그레이드
AWS EKS에서 사용자가 신경써야 할 것은 Worker가 전부다. Master (API) 는 AWS가 알아서 잘 관리하며, 만약 문제가 있을 경우 사용자 모르게 알아서 고친다. 우리는 Worker 노드만 우리의 워크로드에 맞게 잘 조율해주면 된다.
EKS의 Worker 노드들은 AWS Cloudformation 에 정의된
Nodegroup에 의해 관리된다. 지금 내 AWS 콘솔의 Cloudformation 에 들어가보면eksctl이 자동으로 생성한 Nodegroup이 보일 것이다. 이 템플릿이 EC2 Auto Scaling Group도 만들어 알아서 뚝딱 Worker도 올리고, VPC도 만들고, 이것저것 필요한 건 다 한다.그러므로 자연스럽게 클러스터 정보를 업그레이드할때도
Nodegroup을 업그레이드해야 얘가 알아서 나머지를 반영하는 구조가 된다. 어려울 것 같지만eksctl을 사용하면 의외로 쉽게 처리할 수 있다.마찬가지로 더 많은 옵션은 eksctl 공식 문서에서 찾아볼 수 있다.
eksctl create nodegroup --cluster=<클러스터_이름> --region=<AWS_REGION> --nodes=<worker_node_갯수> --node-ami=<EKS_AMI_ID, 혹은 auto> --node-type=<EC2_인스턴스_종류>이 명령어는 내가 지정한 클러스터에 새로운 설정을 담은 새로운
Nodegroup을 만들어준다.Nodegroup은 곧 자동으로 새로운 Worker들을 생성해 클러스터 붙혀준다. 다른 타입의 Worker들을 만들고 싶거나 쿠버네티스 버전 (AMI) 를 업그레이드 하고 싶을 경우 들에 유용하다. 이전Nodegroup이 필요가 없어졌다면, 아래 명령어로 삭제하면 된다.eksctl delete nodegroup --cluster=<클러스터_이름> --region=<AWS_REGION>클러스터 삭제하기
클러스터 잘 가지고 놀았고 이제 치우고 싶을 때, 아래 명령어로 쉽게 삭제할 수 있다.
eksctl delete cluster --cluster=<클러스터_이름> --region=<AWS_REGION>끝!
방금까지
eksctl을 사용해 EKS를 전반적으로 둘러보고 맛까지 보았다. 이제 내 진짜 프로덕션 환경을 생각해 다시 클러스터를 세워, 덜 머리아프게 고가용성 워크로드를 돌려보자.eksctl로 복잡한 쿠버네티스 조금이라도 쉽고 직관적이게 사용하셨으면 좋겠다. 화이팅.나는 고급 옵션이 필요해요
대부분의 경우 위의 명령어로 “범용적인” 클러스터를 만들 수는 있으나, 조금 더 고급 옵션이 필요한 분들은 꼭 계신다. 그런 분들을 위해 몇가지 준비했다. 물론 위에 언급했던 것처럼 공식 문서에서 필요한 것은 다 얻을 수 있지만, 몇가지 정리해봤다. 아래 Flag들은 따로 언급하지 않는 한 클러스터 첫 생성과
Nodegroup생성 둘 다에 쓰일 수 있다.--node-ami=<EKS_AMI_ID, 혹은 auto>Nodegroup생성에서 사용하고 싶은 EKS AMI를 지정할 수 있다.--ssh-access --ssh-public-key=<내_SSH_PUBLIC_키>.pub기본적으로 eksctl이 만든 Worker 노드들은 SSH 접속이 막혀있다. 이 명령어를 사용하면 클러스터 생성 시 내가 사용하고 싶은 키를 연결할 수 있다.
--ssh-public-key=<내_AWS에_등록된_키>로 이미 내 EC2 리전에 등록된 SSH 키를 바로 연결도 가능하다.--node-volume-size=50기본적으로 EKS의 Worker 노드 저장공간은 20GB다. 대부분의 경우 실 워크로드에는 EBS 볼륨은 연결해 사용하니 크게 지장은 없지만, 만약 높은 저장공간이 필요한 경우 이 명령어처럼 GB 단위를 직접 기입해 늘릴 수 있다.
--node-private-networkingWorker 노드들을 Private VPC에 위치시키고 싶은 경우, 이 명령어를 통해 Private VPC를 생성해 해당
Nodegroup의 노드들을 안에 위치시킬 수 있다.eksctl create cluster \ --vpc-private-subnets=subnet-0ff156e0c4a6d300c,subnet-0426fb4a607393184 \ --vpc-public-subnets=subnet-0153e560b3129a696,subnet-009fa0199ec203c37이미 만들어둔 VPC를 사용해 클러스터를 생성하고 싶은 경우, 이 명령어처럼 VPC 서브넷 아이디를 직접 지정해 만들 수 있다.
다른 옵션들이 궁금하다면 위에 걸어둔 링크를 타고 공식 문서를 살펴보자.
-
스스로 Kubernetes 클러스터 구축하기

자. 새로운 주제의 새로운 시작이다.
단순한 흥미 목적이 됐건, 프로덕션 서비스를 꿈꾸고 있던 간에, 모든 일의 시작은 환경 구축이다. 정말 다행인 건, 쿠버네티스가 점점 유명해지고 활발하게 쓰이는 만큼 사용도 편하게 할 수 있도록 다양한 도구와 서비스가 나오고 있다는 점이다. 요즘은 AWS나 GCE같은 퍼블릭 클라우드 사업자에서 원클릭 쿠버네티스 클러스터 서비스도 제공하고 있다.
그렇지만, 첫 단추부터 잘 꿰어야 한다고 하지 않나. 설령 내 클라우드 사업자가 쿠버네티스 서비스를 제공하지 않더라도, 혹은 온프레미스 환경을 사용해야 한다고 해도 문제업이 쿠버네티스 클러스터를 구축할 수 있도록, 오늘 우리는 kubeadm 이라는 도구를 사용할 것이다.
본격적인 구축에 앞서…
kubeadm은 가장 빠르고 간단하게 미니멀한 쿠버네티스 클러스터를 구축할 수 있는 쿠버네티스 공식 인증 도구다. 많은 사람들과 가이드에서도 kubeadm 사용을 권장하고 있으니 혹여나 여기서 다루는 내용이 비표준일 것이라는 걱정은 안 해도 된다.
필자의 테스트 환경은 아래와 같다.
- Ubuntu 16.04 1vCore / 1GB - master - Ubuntu 16.04 1vCore / 2GB - node1 (slave) = Ubuntu 16.04 1vCore / 2GB - node2 (slave)잠깐. master? node? 생소한 단어가 막 나온다. 아니, 얼핏 개념은 알 것이다. master가 책임자고 node가 일하는 녀석이라고 말이다.
바로 그거다. 쿠버네티스에서도 크게 달라지는 것은 없다. master에는 쿠버네티스 전체를 제어할 수 있는 API 서버나, 쿠버네티스 클러스터에 관한 정보를 저장하는 etcd 저장소 등이 구동된다. node가 진짜 일꾼이다. 우리가 앞으로 올릴 애플리케이션 컨테이너는 바로 node에서 구동될 것이다. 이 개념을 감안해 본인의 환경에 맞게 적절하게 테스트 환경의 리소스를 조절하길 바란다.
master 구성하기
먼저 master에 ssh 접속한 후, 다음 명령어를 통해 필요한 패키지를 설치해보자.
sudo apt-get update sudo apt-get install -y docker.io apt-get update && apt-get install -y apt-transport-https curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl자. 방금 우리는 명령어 몇 줄을 통해 깡통 머신에 도커 데몬과 쿠버네티스 클러스터에 필요한 필수 패키지들을 설치했다. 이제 이 녀석을 master로 탈바꿈시켜야 하는데, 그것마져도 간단하다. 다음 한 줄이면 된다.
kubeadm init --apiserver-advertise-address <master_프라이빗_IP> --apiserver-cert-extra-sans <master_퍼블릭_IP> --pod-network-cidr=10.244.0.0/16간단하다고는 했는데, 뭐가 좀 많다? 하나하나 짚어보자.
--apiserver-advertise-address는 master의 메인 IP 주소. node들이 직접 붙을 바로 그 주소다. 당연히 보안상 프라이빗 네트워크를 사용하는 편이 좋으니, master 서버의 프라이빗 IP를 기입하자.--apiserver-cert-extra-sans는 추가적으로 인증에 사용할 IP 주소. 외부에서 쿠버네티스 클러스터에 접근할 수 있는 편이 관리 측면에서 월등하게 편리하니, master의 퍼블릭 IP를 기입한다.--pod-network-cidr는 조금 다른 녀석인데, 쿠버네티스 클러스터에서 구동되는 모든 구성요소 (컨테이너) 등은 자체적인 오버레이 네트워크를 통해 서로 통신한다. 쿠버네티스가 자체적으로 제공하는 오버레이 네트워크 솔루션은 없고, 서드파티를 사용해야 하는데 그 중 우리가 사용할 것은 가장 대중적으로 사용되는 Flannel 이다.10.244.0.0/16이 바로 Flannel이 요구하는 CIDR 범위임으로 init시 지정해줘야 추후 사용에 무리가 없다.초기 셋업 과정들이 자동으로 진행된 후, 완료되었다는 메시지와 함께
kubadm join으로 시작하는 명령어가 출력되었을 것이다. 이것을 복사해서 한쪽에 잘 보관해두자. 눈치가 빠른 분들은 알아차렸겠지만 추후 이 명령어를 사용해 node들을 master에 연결시킬 것이다.거의 다 왔다. 방금 만든 쿠버네티스 master에 오버레이 네트워크 플러그인만 설치하면 된다. 바로 위에서 다룬 Flannel을 말하는 것이다.
cp /etc/kubernetes/admin.conf $HOME/ chown $(id -u):$(id -g) $HOME/admin.conf export KUBECONFIG=$HOME/admin.conf위 과정을 통해
KUBECONFIG파일을 사용할 수 있도록 준비시킨다. 쿠버네티스 클러스터의 접속 정보가 담긴 일종의 열쇠라고 생각해도 무방하다.sysctl net.bridge.bridge-nf-call-iptables=1 kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml오버레이 네트워크가 작동할 수 있도록 방화벽을 약간 만져주고, 플러그인을 설치해 보자. 여기에 쓰인
kubectl apply -f명령어는 앞으로도 자주 쓸 녀석이다. 쿠버네티스의 대부분의 애플리케이션 생성, 기타 구성 과정 등은 yaml 파일에 저장된 구성 정보를 읽어 이루어진다. 방금 우리는 온라인 저장소에서 파일을 가져와 바로 쿠버네티스 클러스터가 읽게 만들었다.이제 쿠버네티스의 뿌리가 갖춰졌으니, 이제 간단히 커뮤니케이션을 해보자. 아래 과정을 통해 쿠버네티스 API에서 현재의 클러스터 구성 상태를 불러올 수 있다.
kubectl get nodes나의 master 노드와 현재 상태 (Ready) 가 보이는가? 잘 따라오고 있다!
클러스터에 node 추가하기
기본 베이스는 master와 다르지 않다. 동일한 Docker 데몬, 동일한 kubelet 등 쿠버네티스 의존성을 요구한다.
node가 될 서버에서 아래 과정을 통해 필요한 물밑작업을 진행하자.
sudo apt-get update sudo apt-get install -y docker.io apt-get update && apt-get install -y apt-transport-https curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF apt-get update apt-get install -y kubelet kubeadm kubectl여기까지 따라왔다면 다른 것은 딱 하나, 최초의 master에서는 init 과정을 통해 클러스터를 생성했다면, 이제 node에서는 join 커멘드로 이미 생성한 클러스터에 참여하면 된다.
위에서 언급한 join 커멘드 복사본을 가져와 node에 붙혀넣기한다. 다음과 같은 형태로 존재한다.
kubeadm join <MASTER_IP:PORT> --token <TOKEN> --discovery-token-ca-cert-hash sha256:<HASH>잠시 시간이 지나고, master에서
kubectl get node커멘드를 실행하면 우리가 추가한 node까지 같이 출력되는 모습을 볼 수 있다. Ready 사인이 들어와 있으면 사용 준비 완료.클러스터 시각화하기
로컬 머신에서 쿠버네티스 클러스터에 접근하고 싶을 경우, 서버에 있는 KUBECONFIG 파일을 옮긴 후 열어 프라이빗 IP가 적혀있는
server부분을 master의 퍼블릭 IP로 교체해 주어야 합니다. kubectl 설치가 따로 필요할 경우, 이 곳을 참조하세요.방금 우리는 사용 가능한 쿠버네티스 클러스터를 완성시켰다! 그래, 다 좋은데, 이제 뭘 해야 할까? 아직 쿠버네티스에 전혀 익숙하지 않은데, 이 검은 창만 보며 모든 일을 진행해야 하는 걸까?
다행히 아니다. 쿠버네티스는 아래와 같은 멋진 공식 웹 UI를 제공한다. 다만 따로 설치해야 할 뿐. 하지만 쿠버네티스를 처음 사용하는 사람에게는 좋은 실습과 적응 과정이 될 수 있다. 자, 따라오자.
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard.yaml이제 쿠버네티스 시스템이 알아서 필요한 파일을 다운로드받아 대시보드를 구동시킬 것이다. 위의
kubectl apply -f명령어는 영어 그대로, kubectl을 통해 file (-f)을 적용시키는 일을 한다. 방금 예시처럼, 앞으로 대부분의 쿠버네티스 리소스 생성은 완성된 yaml 파일을 통해 이루어질 것이다. 일단 파일을 완성만 하면 그 어떤 쿠버네티스 환경에서도 똑같이 구동된다. Infrastructure-as-Code가 피부로 확 체감되는 순간이다.얘기는 나중에. 기껏 대시보드를 설치했으니 직접 접속해보자.
쿠버네티스에서는 대시보드의 접속에 kube-proxy를 사용할 것을 권장한다. 쿠버네티스 API를 통해, 컨테이너 네트워크에 직접 붙어
localhost를 통해 내부 구성요소들에 접속할 수 있게 해주는 컨셉인데, 이를 사용하면 로컬 머신에서의 컨테이너 (혹은 서비스) 접근을 위해 외부 네트워크로 포트를 열지 않아도 된다. 쿠버네티스 대시보드도 마찬가지로 외부에 그냥 오픈할 경우 여러가지 보안 문제가 생길 수 있다. 조금 불편하더라도 프록시를 사용해 접속하도록 하자.아래 명령어로 바로 kube-proxy를 구동할 수 있다.
kubectl proxy (&를 뒤에 붙혀 백그라운드 구동 가능)별다른 에러가 발생하지 않는다면, 이제 내 로컬 머신이 클러스터 내부 네트워크에 붙었다는 소리다. 웹브라우저에서 아래 주소로 접근하면 대시보드가 반갑게 환영해줄 것이다.
https://<master-ip>:<apiserver-port>/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
빰. 어렵게 어렵게 만났다. 근데 잠깐만, 로그인을 하라고 한다. kubeconfig 파일 또는 토큰을 입력해야 하는데, 아마 지금 가지고있는 kubeconfig를 넣어도 로그인이 안될 것이다. 파일 안에 토큰 정보가 들어있지 않기 때문이다. 우리는 어드민 권한으로 로그인하고 싶으니, 어드민 권한을 가진 클러스터 내부 계정을 하나 만들어 토큰값을 뽑아보자. 아래의 코드를 긁어
yaml형태로 저장한 후, 클러스터에 적용하는 것부터 시작하자.apiVersion: v1 kind: ServiceAccount metadata: name: dashboard-admin namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: dashboard-admin roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: dashboard-admin namespace: kube-system모든 yaml 파일 적용은 조금 전 해봤던 것과 같이,
kubectl apply -f <파일_경로>명령어를 사용하면 된다.콘솔에 무언가 만들어졌다고 주르륵 떴는데, 토큰값은 따로 보이지 않는다. 괜찮다, 정상이다. 이제 계정만 만들어졌을 뿐, 토큰은 우리가 뽑아야 한다.
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep dashboard-admin | awk '{print $1}')위 명령어를 통해 토큰값을 얻을 수 있다. 값을 복사한 후 대시보드 로그인 창에 넣어보면 정상적으로 메인 화면이 나오는 것을 볼 수 있다. 일일히 토큰값을 복사하는게 귀찮다면 kubeconfig 파일에 입력할 수도 있는데, 아래의 예시를 따라하자. 파일 형태는 조금 다를 수 있으나 위치는 동일하다.
apiVersion: v1 clusters: - cluster: certificate-authority-data: (...) server: (...) name: (...) contexts: - context: cluster: (...) user:(...) name: (...) current-context: (...) kind: Config preferences: {} users: - name: (...) user: token: <여기에 토큰값> exec: (...)정상적으로 입력했다면, 로그인 창에서 kubeconfig 파일을 선택하는 것으로 접근이 가능할 것이다.
Hello, World?
방금 전 과정까지 해서 우리는 직접 깡통 머신에 쿠버네티스를 설치하고, 클러스터를 구성하고, 대시보드 애플리케이션 구동과 내부 계정 생성까지 모두 해보았다. 아직은 어벙벙 하겠지만, 앞으로의 쿠버네티스 사용 대부분은 방금 우리가 거쳐온 방법들을 사용한다. 역시 맛보기로는 직접 만들어보는 것처럼 좋은 일이 없다.
이제 막 클러스터가 만들어졌으니, 무언가 자꾸 올려보고 싶은 건 당연하다. 아래의 링크들을 참조하면 여러가지 데모 애플리케이션을 직접 실행하며 감을 잡을 수 있을 것이다.
마지막으로 이 글을 정독한 모두에게, 클러스터 오케스트레이션 세상에 첫 발을 내딛을 걸 환영한다고 박수를 쳐주고 싶다. 처음 접근은 어려울 지 몰라도, 한번 익숙해지면 이전의 서버 운영과는 차원이 다른 편안함과 유연함을 맛볼 수 있을 것이라 장담한다.
그리고 다음에 다룰 내용에 관한 글도 하나 첨부한다. 기존의 쿠버네티스 yaml 파일도 쓸만은 하지만, 너무나 정적인 탓에 같은 애플리케이션 (또는 이미지) 기반으로 여러 환경을 만들어야 할 경우 그 환경들을 위한 모든 yaml 파일을 만들어야 하는 등 단점이 명확한데, Helm 이라는 패키지 매니저가 그런 문제를 해결해줄 수 있다. 자세한 내용은 다음에 다루겠다.
-
나도 Kubernetes 써보고 싶어요!
안녕 독자들. 주인장은 아직 살아있다. 마지막 글을 1월에 남기고 쭉 잠수를 탔는데, 그 사이 정말 많은 일이 있었다. 처음으로 한 회사에 들어가 많은 경험을 했지만, 그리 행복하지 않았기도 했고… 이전에는 생각하지도 않았던 여러 요소들에게 스트레스도 많이 받았다. 결국 3개월만에 그 곳을 나오고 다른 곳을 물색하다 우연히 bitHolla라는 암호화폐 관련 기술을 다루는 스타트업에 DevOps 엔지니어로 참여하게 되었다.
비트홀라는 여러 암호화폐 거래소에 동시에 연결해 빠른 거래를 할 수 있게 해주는 트레이딩 터미널 - XRayTrade와, 직접 암호화폐 거래소를 개설할 수 있게 도와주는 거래소 플랫폼 - HollaEx를 서비스하고 있는 스타트업이에요. 외국인들로 구성된 기업이라 영어로 일할 수 있다는 점, 쓸데없는 규율이 존재하지 않아 마음 편하게 하고싶은 일을 할 수 있다는 점이 너무 마음에 들어 만족하며 일하고 있어요.
필자가 비트홀라에서 담당하고 있는 일 중, 가장 중요하고 궁극적으로 이루려고 하는 일이 모든 인프라의 쿠버네티스 마이그레이션이다. 기존 인프라는 도커화(dockerize)는 되어 있지만, 모던 아키텍처가 요구하는 컨테이너 오케스트레이션은 이루어지지 않고 있는 상태. 지금의 서비스에는 큰 문제가 없지만, 추후 규모가 커졌을 때의 자유로운 스케일 업 / 다운, 장애 복구, 그리고 빠르고 간편한 코드 배포를 위해 쿠버네티스를 대체 솔루션으로 선택했다.
물론 필자가 이전에 다뤘던 것 처럼, 도커 네이티브로도 Docker Swarm이라는 컨테이너 오케스트레이션 솔루션이 존재한다. 그렇지만, 최근의 업계 트렌트와 이 둘의 지원하는 기술 차이, 외부 단체의 서포트 정도 등을 봤을 때, 쿠버네티스가 현재 사용할 수 있는 가장 발전되고 미래가 유망한 오케스트레이션 솔루션이라는 결론이 나왔다.
여러분 모두 쿠버네티스 하세요!!
잠깐만요. 그래서, 쿠버네티스가 뭔데요?

쿠버네티스 (또는 줄여서 k8s)는 한 줄로 정리하자면 도커 컨테이너 기반 서비스 그 자체를 쉽게 이룰 수 있게 도와주는 궁극적인 플랫폼 이라고 할 수 있다.
착각할 수도 있는데, 쿠버네티스와 도커는 별개가 아니다. 쿠버네티스는 도커 데몬과 연결되어 기존에 수동으로 하나하나 설정하던 모든 작업을 쿠버네티스 단에서 처리할 수 있게 해준다. 일종의 도커라는 컴퓨터를 굴리는 운영체제라고 생각하셔도 좋다.
쿠버네티스를 사용하면 여러 도커 호스트(서버)를 하나의 클러스터로 쉽게 묶어 서비스를 배포할 수 있다. 여기서 어떤 호스트에 얼만큼 컨테이너를 분배할 지 등도 쿠버네티스가 자동으로 결정해준다. 기존 도커 호스트를 따로따로 운영하는 것보다 더 효율적인 자원 분배가 가능하다는 말이다. 물론 어떤 호스트에 어떤 컨테이너가 있는지 따로따로 기억할 필요도 전혀 없어지게 된다. 자체적인 이미지(코드) 배포 기능을 가지고 있어 기존 서비스의 중단 없이 신 버전 코드로 업데이트도 가능하고, 추가적인 외부 저장소(AWS EBS 등)를 쿠버네티스 클러스터 자체와 마운트해 데이터베이스 같은 Stateful한 애플리케이션도 문제없이 운영할 수 있고 말이다. 뿐만 아니라, 내 서비스가 유지해야 할 필수 동작(설정) 선언에 따라 클러스터가 스스로 똑같은 상태를 유지한다. 도커 호스트 일부가 다운되는 등 문제가 발생하더라도, 현재 사용할 수 있는 자원을 파악해 새로운 호스트로 즉시 똑같은 구성의 컨테이너를 생성한다.
휴, 이제 숨 쉬셔도 됩니다. 어때요. 여기까지만 들어도 사용해보고 싶은 마음이 확 들지 않을까?
함께 조금만 참자. 앞으로 일종의 시리즈 물처럼 쿠버네티스 클러스터의 구축부터, 현재 도커화해서 사용하던 애플리케이션의 쿠버네티스 레시피화(yaml 파일), Helm 패키지 매니저를 통한 더 쉬운 애플리케이션 배포, Jenkins 등의 CI 도구를 사용하는 애플리케이션 배포 자동화까지 모두 다룰 예정이다. 앞으로의 글만 살펴봐도 즉시 쿠버네티스를 사용할 수 있게 말이다!
다음 글이 업로드되면 이 글 아래에 링크를 달아 둘 예정이다. 그동안 아래의 문서들을 읽고 있으면 도움이 될 것 같다.
사실 이번 글부터 말투를 조금 부드럽게 바꿔볼려 했는데, 다시 들여다보니 손발이 오그라들어 일부분 (이라고 쓰고 거의 다) 예전 스타일로 롤백했다.
Helm rollback kycfeel.github.io <OLD_RELEASE>참고 문서
다음 글