-
어서오세요. Docker의 세계에.
Hello, Docker!

Docker. 많이 들어보셨을 것이라 생각한다. 개발자가 VM의 늪에서 허덕일 때 나타난 구세주가 아닌가? 필자는 개발자(Dev) 보다는 시스템 엔지니어(Ops) 계열이기에 더더욱 Docker를 사용할 일이 많다. 다만 요근래 취직을 못해서 관련 지식은 있어도 직접 다룰 일은 거의 없었는데, 얼마 전 면접을 보고온 스타트업에 들어가게 되면 Docker를 바로 업무에서 사용할 것 같기에 결과 기다리는 시간 중 김칫국 마시며 Docker를 되짚어 보려 한다. 이 포스트부터 철저히 필자에게 초점이 맞춰진 Docker 이야기를 시작하겠다. 최대한 noob부터 pro까지 포괄적인 커버가 가능하게 글을 작성하려 하니 모두에게 도움이 됬으면 좋겠다.
Docker?
대체 Docker가 무엇인데 그러냐? VM의 늪에서 구원을 해준다는게 뭔 소린가? 도구는 사용할 목적이 있어야 빛을 낸다. 처음 Docker를 만나는 분들에게는 당연하고도 중요한 질문이다. 그런데 Docker 자체를 만지기에 앞서 컨테이너 기술부터 이야기를 시작하겠다. 영어로 무언가 담을 수 있는 공간을 컨테이너라 한다. 무언가(애플리케이션, 서버)를 담을 수 있는 공간을 만들어주는 기술. 그게 컨테이너 기술이다. Docker는 그런 컨테이너 기술을 다루는 하나의 플랫폼이다. 개인 PC에서 Docker로 독립된 공간을 만들어 깔끔하게 애플리케이션을 구축하고, 패키지(이미지)로 만들어서 업무 서버에 가져다 넣으면 그대로 작동된다. 다른 사람과 자유롭게 공유도 할 수 있다. 물론 다른 사람이 미리 만들어둔 이미지를 다운받아 조금 뜯어 고쳐 사용할 수도 있다. 어디서 많이 본것들 아닌가? 바로 VM이다. 지금까지 VM이 위에서 말한 일들을 가능하게 했다. 그럼 컨테이너 기술을 사용한다는 Docker와 다른 점은 무엇일까? VM은 하드웨어와 운영체제까지 가상화하지만 컨테이너 기술은 공간만 나눈다. 즉, 호스트 컴퓨터와 운영체제 커널과 시스템 리소스를 공유한다는 소리다. 더 이상 기존 VM처럼 운영체제 가상화 등으로 추가적인 리소스 소모를 하지 않아도 된다는 거다. 당장은 VM을 사용할 때 느끼던 장점은 따오고 단점은 보완한 이상적인 녀석이라고 이해해도 크게 문제는 없을 것 같다. 시간과 글 쓸 공간은 얼마든지 있으니, 더 자세한 Docker의 매력은 차차 진행하면서 알아보도록 하자.
Docker 설치하기
필자는 CentOS를 사랑하니 CentOS 기준으로 아래 내용을 작성했다. 혹시 레드헷 배포판을 사용하지 않는 분들은 여기를 참고하시면 된다.
sudo yum install -y yum-utils위 명령어로
yum-utils를 설치하고 시작하자.sudo yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo위 명령어는 Stable 버전의 Repo를 등록해준다. 참고로 저기 도메인 끝의
docker-ce는 무료 버전을 뜻하는 Docker Community Edition의 줄임말이다. 혹시 정말 중요한 기업 시스템을 돌리기 위해 Docker를 알아보고 있고 전문 기술팀의 지원이 있으면 좋을 것 같다는 분들은 이것을 읽어 보시길 바란다.sudo yum makecache fast이제 위 명령어로 yum 패키지 목록을 업데이트한다.
sudo yum install docker-ce업데이트가 끝났으면 위 명령어로 Docker를 설치하면 된다. 참 쉽죠?
혹시라도 특정 버전의 Docker를 정해 사용해야 하시는 분들은 위 명령어 뒤에 원하는 버전을
sudo yum install docker-ce-<VERSION>이런 식으로 붙혀 주시면 된다.sudo systemctl start docker sudo systemctl stop docker설치가 완료된 Docker는 다른 애플리케이션과 마찬가지로 위처럼 제어할 수 있다.
Docker 이미지와 컨테이너
VM에서의 ‘이미지’를 떠올려 보자. 가상화된 OS, 변경점, 데이터 등 모든 것이 이미지에 들어 있고, 그 이미지를 복사해서 똑같은 VM을 다른 곳에 또 생성할 수도 있다. Docker에서의 이미지도 크게 다르지 않다. 필요한 애플리케이션이나 라이브러리, 데이터 등이 들어있는 저장 단위이다. 고맙게도 Docker는 Docker Hub라는 자체 저장소 서비스를 제공한다. 이곳에서 사람들이 만들어 둔 수많은 이미지를 필요에 맞게 끌어와 사용할 수도 있고, 내가 만든 이미지를 다른 사람들과 나눌 수도 있다. 혹시 VM에서의 복잡하고 용량 큰 이미지 공유를 생각했다면 잊어도 좋다. Docker는 이미지 공유를 처음부터 생각하고 디자인 된 플랫폼이다. OS 가상화 데이터 등 VM 이미지에서 가장 부피를 많이 차지하던 것들이 없어져 대부분의 Docker 이미지는 생각보다 크기가 아주 작다. 거기에 Docker는 유니온 파일 시스템을 사용해 이미지의 각 정보를 계층(레이어) 단위로 나눠 저장하여 새로운 이미지를 끌어온다 하더라도 내가 이미 가지고 있는 정보가 있다면 그 부분은 생략해주는 멋진 능력까지 가지고 있어 실 체감 용량은 훨씬 적어지기도 한다.프라이빗한 사용이 필요할 경우 자체 저장소 서버를 구축하거나 GitLab 등에서 제공하는 팀 전용 컨테이너 저장소를 이용하는 등 방법은 아주 많으니 필요에 맞게 선택하면 된다.
이제 이미지는 대충 알겠는데, ‘컨테이너’는 뭘까? Docker 이미지를 실행한 것이 바로 컨테이너다. 별 것 없다. 이미지는 각종 필요한 데이터가 저장되있는 파일. 그리고 그것을 실행한 것이 컨테이너. 이렇게 생각하면 된다. 혹시 기존에 Docker를 인터넷에서 검색해본 경험이 있다면 이미지와 컨테이너가 같이 언급되는 것을 본 적 있을 것인데, 입문자에게는 두 개념이 혼동될 수 있는 위험이 있어 최대한 짧고 간결하게 정리했다.
주절주절 이미지와 컨테이너에 대해 떠들어봤는데, 이제 직접 만져보는 시간을 가져야 흥미가 떨어지지 않을 것이다. 터미널을 띄우고
docker -v명령어를 입력해 아까 설치한 Docker가 제대로 설치되었는지 확인하자.sudo docker run hello-world위 명령어는 “Hello World”를 출력하는 테스트 이미지를 Docker Hub에서 다운로드해, 바로 실행까지 해주는 역할을 한다. 정상적으로 문구가 출력되었다면 이제 Docker의 세계에 본격적으로 발을 담굴 준비가 되었다는 뜻이다. Docker에는
run뿐만 아니라 여러 강력한 명령어들이 존재한다. 이 블로그에 아주 훌륭하게 정리가 되어 있으니 꼭 참고하길 바란다.예를 들어, 최신 Ubuntu 컨테이너를 실행하고 싶으면 아래처럼 입력하면 된다.
sudo docker run -i -t ubuntu참고로 저기
run명령어 뒤에 붙은-i,-t옵션들은 각각 상호작용을 뜻하는 interactive와 터미널을 뜻하는 Pseudo-tty다. 필자도 머리 아프니 너무 깊게 생각하지 않아도 된다. 위 명령어를 실행했으면 최신 Ubuntu 이미지를 끌어와 자동으로 컨테이너가 실행된 후, 마치 ssh 연결을 한 것처럼 터미널 입력창까지 바뀌게 된다. 이제 이 독립된 공간에서 자유롭게 해집고 다닐 수 있다. 아, 여기에exit를 입력하면 컨테이너의 전원도 같이 꺼뜨리고 나가지니 주의. 컨테이너를 그대로 살려둔 상태로 나가길 원한다면ctrl + p,ctrl + q를 순서대로 누르면 된다.수고 많으셨다. 앞으로 이어질 포스트에서 자세한 활용 방법과 관련 도구 등을 다룰 예정이니 잠깐 휴식하는 시간을 가지길 바란다 :)
-
민주주의가 승리한 날, Replica 무료 배포
Replica?

Replica는 모든 국민이 국가에 의해 감시, 통제당하는 디스토피아 사회를 그린 게임이다. 고정된 도트 그래픽의 화면에서 스마트폰을 이리저리 누르는 것으로 진행되는데, 한국인 개발자가 만든 게임이라 그런지 국내에서 벌어진 각종 사안 (국정원의 카카오톡 감청, 언론 통제나 게임 중독 등)이 신랄하게 녹아있어 필자도 출시 직후 구매해 인상깊게 즐긴 게임이다.
그리고 바로 오늘. 2017년 3월 10일. 대한민국에서 민주주의가 승리한 날에 Replica의 개발자 SOMI가 하루동안의 Replica의 무료 배포를 선언했다. 달콤한 민주주의를 맛보며 감사하는 마음으로 게임을 즐기도록 하자. 평소 달랑 게임이 무료 배포 행사를 한다고 일일히 GitHub 페이지에 올리는 일은 없다. 다만 오늘같은 날이면 이런 특별한 게임이면 또 상황이 달라지지 않는가.
이곳에서 Windows와 macOS용 Replica를 다운로드 받을 수 있다.
대한민국의 주권은 국민에게 있고, 모든 권력은 국민으로부터 나온다. - 대한민국 헌법 제 2항.
-
Tor 네트워크를 사용해 익명 웹서버 구동하기
익명 웹서버를 구동하는 목적
이것을 설명하기 위해서는 “왜 익명 네트워크가 필요한가?” 라는 이야기를 먼저 할 필요가 있다. 분명 우리가 살고있는 이 세상은 인종이나 경제력, 문화, 태어난 곳 등에 따른 차별이나 제한 없이 누구나 원하는 정보에 접근하고 원하는 말을 온라인 공간에 나눌 수 있어야만 한다. 그런데, “국민들에게 유해한 정보를 막는다.” 라는 이유로 정상적인 정보들을 필터링하고, 하고싶은 말을 하면 뒷보복을 두려워해야 하는 국가들이 아직도 전 세계에 많이 남아있다. 대한민국도 정도는 비교적 낮지만 이런 ‘인터넷 검열’ 국가 중 하나이고, 흔히 우리가 유머거리로 삼는 Warning 사이트도 그 검열의 흔적이다. 대표적으로 이런 국가적인 검열을 피하기 위해 익명 네트워크가 사용되지만, 물론 기업의 내부고발자가 익명성을 위해 사용하거나, 보안이 필요한 단체끼리 통신 목적으로 사용하는 등 사용처는 무궁무진하게 만들 수도 있다. 우리가 사용할 도구는 좋은 의미로도 나쁜 의미로도 유명한 Tor다. Tor의 Onion 네트워크 위에 완벽한 익명성을 꿈꾸는 사람들을 위한 웹서버를 구동해 보자. 접속하는 사람도 익명, 서버를 구동하는 우리도 물론 익명이다.
하드웨어 준비물
물론 소프트웨어적인 준비물은 아래의 과정에서 잘 설명하겠지만, 그걸 받아들일 수 있는 하드웨어 준비물은 미리 준비해 주시길 바란다. 제대로 서버를 계속 유지할 것이 아니라면 지금 사용하는 컴퓨터로도 충분하다. 필자는 저전력과 Unix 환경 모두 확보할 수 있는 라즈베리 파이 3를 기준으로 이 글을 작성하였다. Windows 환경도 기본적인 개념은 모두 같으나, 쉽게 따라할 수 있도록 Debian 기반 가상머신을 생성한 후 따라하는 것을 강력 추천한다.
혹시 정 Windows 환경을 고집하고 싶다면 이 글 을 참고하자. 다른 블로거분이 한국어로 잘 정리해 주셨다.
웹서버 구성요소 준비하기
이 포스트는 웹서버를 익명으로 굴리는 방법을 알려주는 포스트다. 익명으로 굴릴 웹서버 구성 요소들은 미리 만들어 주셔야 한다. 물론 아래의 과정을 밟고 만들어도 상관은 없으니 난 결과물을 먼저 뽑고 싶다! 하면 아래 과정 먼저 따라와도 된다. 테스트를 위해 “Hello World!”가 박힌
index.html파일 정도만 준비하자. 서버는 어떤 소프트웨어를 사용하던 상관 없다. 필자는 이 글에서 Node.js를 사용하여 웹서버를 구동하도록 하겠다. 웹서버가 준비되었다면 가상머신 한곳에 모셔두면 된다.설치하고 구동하기
아래 내용은 공식 메뉴얼을 참고해 작성되었다.
자, 서론이 길어졌다. 당장 터미널을 열고
sudo apt-get update명령어로 패키지 리스트를 업데이트한 뒤, 아래 명령어를 입력하자.sudo apt-get install Tor설치는 정말 이 한 줄로 끝난다. 정말이다. 이제 설정만 조금 잡아주면 된다. 정상적으로 설치가 되었다면
/etc/tor/torrc파일이 존재할 것인데, 좋아하는 텍스트 에디터로 열어 보자. 조금 내리다 보면############### This section is just for location-hidden services ###안내가 보일 것인데, 잘 찾아 오셨다. 안내와 같이 여기서부터 우리가 찾던 익명 서버 관련 설정을 할 수 있다. 아마 아래와 같은 값이 보일 거이다.#HiddenServiceDir /Library/Tor/var/lib/tor/hidden_service/ #HiddenServicePort 80 127.0.0.1:8080대충 감이 오지 않는가? 위
HiddenServiceDir은 익명으로 구동할 웹서버가 위치하는 경로,HiddenServicePort는 그 서버의 웹 포트이다. 주석(#)은 당연히 모두 지워주고 위에 웹서버가 위치하는 곳의 경로를 지정해준다. 아래는 그냥 놔두면 된다. Tor로 구동되는 서버는 localhost로 1차 구동되고 Onion 네트워크를 타고 외부로 나가는 것이라 저 설정이 맞다.sudo service tor restart명령어로 Tor를 재시작했을 때 아까 지정한HiddenServiceDir에hostname이나private_key파일이 생성되었다면 정상적으로 설정된 것이다. 사용자 권한으로는 안 보일 수 있으니root로 확인하길 바란다. 만약 그렇지 않다면,/var/log/tor에 들어가 로그 파일을 살펴보자.정상적으로 위 과정을 모두 마쳤다면, 이제 생성된
hostname파일에 들어가보자.duskgytldkxiuqc6.onion와 같은 Onion 네트워크 도메인이 들어있을 것인데, 이게 앞으로 내 익명 웹서버의 접속 주소가 된다. 이제 웹 서버를 가동해자. 필자는 상기했듯 Node.js 기반으로 테스트 서버를 가동하니HiddenServiceDir경로에서node app.js명령어를 사용했다. 다른 종류의 CMS를 사용하는 경우 알아서 실행하시길 바란다.반영까지 1분여 기다린 후, 다른 컴퓨터 (가상머신 밖)에서 Tor 브라우저로 위 주소에 접속해보자. 정상적으로 웹사이트가 출력되면 성공. 당신도 이제 익명 네트워크에 기여하는 훌륭한 기여자가 됬다.
일반 브라우저로 접속하기
Onion 주소는 Tor 브라우저로만 접속할 수 있다. 물론 Tor 유저들끼리는 별 문제가 없겠지만, 전세계 모든 인터넷 이용자들이 Tor를 사용하지는 않지 않는가. Tor2Web이라는 서비스가 이 문제를 해결해줄 수 있다. 내 Onion 도메인 (예시:
duskgytldkxiuqc6.onion)의 끝.onion부분을.onion.link로 바꿔주면 끝.duskgytldkxiuqc6.onion주소는 Tor 브라우저 전용이지만,duskgytldkxiuqc6.onion.link주소는 일반 웹 브라우저에서도 사용할 수 있다. 다만 접속자의 익명성 확보는 Tor를 사용하는 것보다 훨씬 어려우니 주의. -
OpenStack에 CloudKitty 연동하기
CloudKitty?
CloudKitty 는 OpenStack을 위한 Rating-as-a-Service 프로젝트다. 다시 말해, 기존 OpenStack에 구현되어 있지 않은 Pricing이나, Billing 같은 기능을 추가해 사용할 수 있다는 거다. OpenStack의 Ceilometer 와 연동되어 사용량에 따라 과금 정책을 잡는 등 퍼블릭 서비스를 위한 발판으로 삼을 수 있다. 아무래도 OpenStack 자체가 프라이빗 클라우드를 생각하고 디자인된 플랫폼이라 CloudKitty같은 프로젝트는 마이너한 편이고, 한국어 자료는 더더욱 기대할 수 없어 이 포스트가 도움이 될 수 있을 것이다.
CloudKitty 설치하기
최근 리뉴얼된 공식 설치 가이드 를 참고해 Ubuntu 16.04 LTS 기준으로 작성되었다. 아래 과정으로 진행하기 전 적당한 사양의 (1vCore에 1GB만 되어도 테스트 목적으로 충분) VM을 준비해주자.
과거에는
git에서 직접 소스를 다운받아 인스톨하는 과정이 필요했었는데, 이제apt-get으로 간편하게 설치가 가능해졌다. 아래 명령어로 repo를 추가해 주자. 권한 문제가 있으면 명령어 앞에sudo를 적절히 붙혀준다.apt install software-properties-common add-apt-repository ppa:objectif-libre/cloudkittyVM의 패키지를 업데이트 해준다.
apt update && apt dist-upgrade이제 CloudKitty를 설치할 수 있다. 뭘 망설이고 있는가? 당장 받자.
apt-get install cloudkitty-api cloudkitty-processor cloudkitty-dashboard정말 간단하게 명령어 몇 줄로 모든 설치과정이 끝났다. 예전
git에서 소스 가져와 설치하던 때만 하더라도 각종 의존성 문제에 파이썬 오류에 별 난리가 다 났었는데 이건 참 좋아진 것 같다.CloudKitty 설정하기
/etc/cloudkitty/cloudkitty.conf에서 설정 스크립트를 건들 수 있다. 아래는Keystone v3기준 설정 예제다. 만약v2.0기준 예제가 필요하다면 위에 링크를 달아둔 CloudKitty 공식 메뉴얼에서 확인할 수 있다.[DEFAULT] verbose = True log_dir = /var/log/cloudkitty [oslo_messaging_rabbit] rabbit_userid = openstack // rabbit 서비스 userid rabbit_password = RABBIT_PASSWORD // rabbit 서비스 password rabbit_host = RABBIT_HOST // rabbit 서비스가 돌아가는 호스트 IP (OpenStack-Controller) rabbit_port = 5672 [ks_auth] auth_type = v3password auth_protocol = http auth_url = http://localhost:5000/v3 // localhost 부분을 OpenStack-Controller IP 로 변경 identity_uri = http://localhost:35357/v3 // localhost 부분을 OpenStack-Controller IP 로 변경 username = cloudkitty password = CK_PASSWORD // 사용할 password project_name = service user_domain_name = default project_domain_name = default debug = True [keystone_authtoken] auth_section = ks_auth [database] connection = mysql://cloudkitty:DB 비밀번호@localhost/cloudkitty // 아래의 DB 설정 후 정보 집어넣기 [keystone_fetcher] auth_section = ks_auth keystone_version = 3 [tenant_fetcher] backend = keystone [collect] collector = ceilometer period = 3600 services = compute, volume, network.bw.in, network.bw.out, network.floating, image // Ceilometer로 측정할 정보들 [ceilometer_collector] auth_section = ks_auth주요 파라미터들에 주석을 달아뒀으니 설정에 참고하면 된다. 아마 스크립트를 찬찬히 살펴보다 보면
[database]라는 항목이 있었을 건데 지금부터 MySql에 CloudKitty용 DB를 하나 판 후, 위 스크립트에 집어넣어 보겠다.mysql -uroot -p << EOF CREATE DATABASE cloudkitty; GRANT ALL PRIVILEGES ON cloudkitty.* TO 'cloudkitty'@'localhost' IDENTIFIED BY '사용할 비밀번호'; EOF위 명령어로 Mysql에 DB를 만든 후, 다시 스크립트로 돌아가
[database]칸을 방금 생성한 DB 정보로 수정한다. 저장한 후, 공식 메뉴얼과 달리 Keystone 설정 먼저 진행하도록 하겠다.Keystone 설정하기
왜 공식 메뉴얼 안 따라가고 혼자 독주를 하느냐? 물어본다면 답은 간단하다. 공식 메뉴얼을 그대로 따라가면 작동이 안 되기 때문이다. 처음 CloudKitty를 설치할 때 가장 고생했던 부분이 이곳이다. 분명 나는 메뉴얼에 맞춰 따라했는데 작동이 안 되는 것이다. 하루이틀 삽질하다 찾아낸 방법은 Keystone에 역할을 먼저 지정해줘야 한다는 것이다.
keystoneclient로 접속해 아래 명령어로 필요한 계정을 생성해보자. OpenStack-Controller로 돌아와 RDO 설치 기준keystonerc_admin파일이 있는 곳에서. keystonerc_admin명령어로 접속할 수 있다.openstack user create cloudkitty --password 위에서 지정한 비밀번호 --email cloudkitty@localhost openstack role add --project service --user cloudkitty admin이제
rating이라는 새로운 역할을 만들어 cloudkitty를 묶어줄 거다.openstack role create rating openstack role add --project service --user cloudkitty rating위 명령어들의
--project는 본인의 상황에 맞게 골라주면 된다. 여기서는service를 사용했다.이제 마지막으로 Rating 서비스의 API Endpoint를 만들어 줘야 한다. 아래 명령어로 쉽게 생성할 수 있다.
openstack service create rating --name cloudkitty \ --description "OpenStack Rating Service" openstack endpoint create rating --region RegionOne \ public http://OpenStack-Controller IP주소:8889 openstack endpoint create rating --region RegionOne \ admin http://OpenStack-Controller IP주소:8889 openstack endpoint create rating --region RegionOne \ internal http://OpenStack-Controller IP주소:8889여기까지 끝났으면 다시 CloudKitty가 실행되는 VM으로 돌아와 아래 명령어들을 입력한다.
cloudkitty-dbsync upgrade cloudkitty-storage-initCloudKitty 서비스 시작하기
잘 따라오셨다. 정말 마지막으로 CloudKitty 서비스를 어떻게 끄고 키는지만 알고 가자. CloudKitty를 설치한 VM에서 다른 앱들과 같이
systemctl명령어로 제어할 수 있다.systemctl start cloudkitty-api.service systemctl start cloudkitty-processor.service위의 모든 설정이 끝나고 CloudKitty 서비스도 정상적으로 굴러가고 있는가? 이제 OpenStack 대시보드로 접속해 보자. 로그인까지 마치면 이전에는 보지 못한
Rating이라는 메뉴가 보일 것이다. 인스턴스 생성 창에는 가격 표시도 생긴다. 이제 이걸 자유롭게 주물러 보는 일만 남았다. 여러분의 몫이다.마치며
사실 이 정보를 찾는 사람이 얼마나 될 지는 모르겠다. CloudKitty라는 프로젝트가 워낙 마이너할 뿐더러 영어도 아니고 한국어로 작성된 이 포스트에 관심을 가지는 사람은 필자밖에 없을지도 모른다. 그래도 혹시 알까, 누군가 이 포스트를 읽고 도움을 받을지.
-
검색엔진에서 GitHub 페이지 검색 가능하게 하기
왜 이런 일을 해야 하나요?
안타깝게도 기본 설정의 GitHub 페이지는 일반적인 포탈사이트 블로그나 티스토리 등과는 달리 검색엔진에서 백날 검색해도 글이 나오지 않는다. 다시 말해, 아무리 좋은 글을 써놨다고 하더라도 누구 하나 볼 사람이 없다는 뜻이다. 고도로 연결된 정보화 사회의 정점을 달리는 우리들이 이런 고독감을 맛보면 되겠나? 당장 주요 검색엔진들에게 나 자신을 어필해보자.
Google에 내 페이지 노출하기
아무래도 전문적인 내용을 주로 다루게 되는 GitHub 페이지 특성 상, 마찬가지로 한국인들이 전문적인 내용을 주로 검색하게 되는 Google에 최우선적으로 노출시키는 편이 필자나 구독자나 모두에게 좋을 것이다. Google에서는 Search Console 이라는 검색 결과 노출 매니저를 제공한다. 이곳에 내 GitHub 페이지의 도메인을 추가시키는 것으로 시작한다. 아마 중간에 사이트의 주인임을 증명하는 과정이 있을 것인데, 이 포스트를 따라하기 전 Google Analytics를 등록해 둔 적이 있다면 그것과 연동해 바로 주인 인증이 가능하다. 만약 하지 않았다면 이 포스트를 참조하기 바란다.
이제 내 웹사이트 안에
sitemap.xml만들고 GitHub에 Push한 다음 Search Console에 동기화만 해주면 되는데, 고맙게도 내가 사용하는 테마는 이미 제작자가_config.yml에jekyll-sitemap을 정의해 둔 상태였다. 물론 여러분의 경우 그러지 않을 경우가 더 많기에 이 글에서는 플러그인 없이sitemap.xml을 생성해 보겠다.웹사이트 폴더 최상단에
sitemap.xml이라는 이름의 파일을 만들고, 이 페이지 에 올라온 샘플 코드를 그대로 긁어 붙혀넣으면 된다.저장까지 끝냈다면, 한번
jekyll serve명령어로 로컬 서버를 생성해localhost:4000/sitemap.xml도메인으로 접속해 봐라. xml 파일의 내용이 출력되면 잘 적용 된거다. 혹시 모르니 GitHub에 Push한 후 다시username.github.io/sitemap.xml주소로 들어가 제대로 출력되는지 확인해보자. 이제 남은 일은 Search Console에 들어가 sitemap 추가 메뉴에서username.github.io/sitemap.xml주소를 입력해 주기만 하면 된다. 자동으로 포스트를 받아올 것이다. 앞으로 새로운 포스트를 계속 작성하더라도 sitemap이 자동으로 반영할 것이니 더이상 신경쓰지 않아도 좋다.혹시 특정 글의 변경 주기나 우선순위 정보 등을 커스터마이징 하고 싶다면 글 속성에
lastmod나sitemap.changefreq등의 태그를 추가해주면 된다.--- layout: post title: "플러그인 없이 Jekyll Sitemap 만들기" date: 2017-03-03 17:23:40 +0900 categories: Jekyll과 Github 페이지 date: 2017-03-03 17:23:40 +0900 sitemap : changefreq : daily priority : 1.0 ---Naver에 내 페이지 노출하기
일단 Google에 내 포스트가 검색된다면 참았던 숨을 내쉬어도 좋지만, 한국어로 작성되는 콘텐츠가 한국인이 가장 많이 사용하는 검색엔진에 노출되지 않는다면 그것도 서운해진다. 네이버에서도 Google과 비슷한 네이버 웹마스터 도구라는 웹 콘솔을 제공하고 있다. 이 글을 작성하는 시점에는 아직 Beta 딱지가 달려 있지만 뭐 어떤가. 작동만 잘 하면 되지.
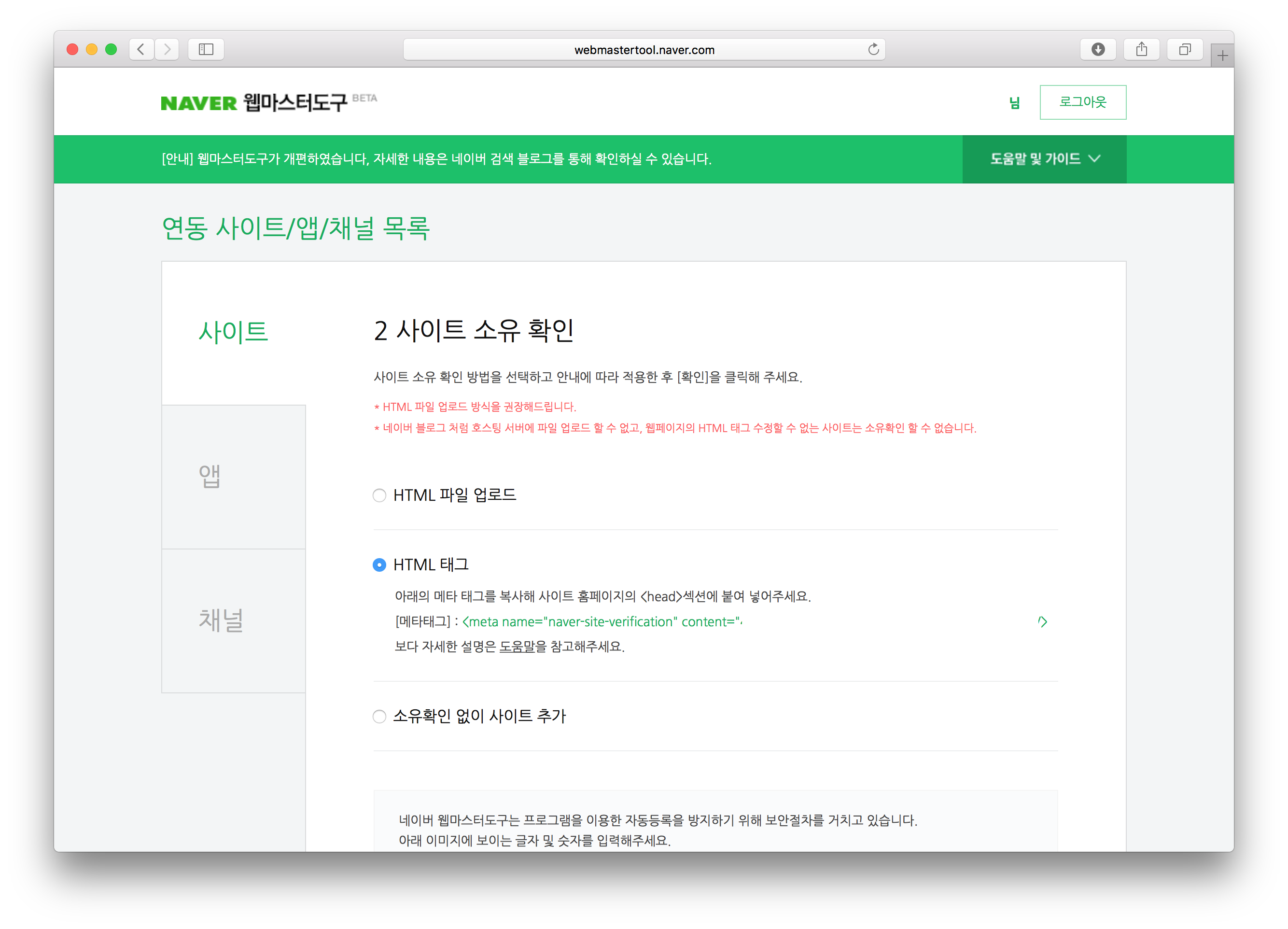
사이트 추가 절차를 진행하다 보면 Google의 경우와 마찬가지로 내 사이트임을 증명하는 과정이 필요하다. html 파일을 다운로드받아 넣는 방법도 있고,
<head>에 네이버에서 제공하는 메타태그를 삽입하는 방법도 있으니 원하는 것을 선택하면 된다. 적용하고 GitHub에 Push 한 후 확인 버튼을 누르면 그대로 인증이 끝나고 사이트가 추가된다. 한국 사이트에서 흔하게 볼 수 없는 깔끔함이다.마치며
평소 타 블로그 서비스를 사용하며 당연하다 생각했던 검색엔진 검색 등록을 수동으로 하려 하니 짜증도 물론 나겠지만, 그만큼 GitHub에서 보장해주는 자유도를 생각하면 뭐 참을만 하기도 하다. 괜히 필자처럼 처음에 햇갈려하지 말고 도움이 되었으면 하는 바람이다. 위의 Google Sitemap 관련 내용은 이 페이지를 참고해서 작성했다. 해당 페이지의 작성자 분에게 감사의 말씀을 전한다.